Lua
Lua是轻量小巧的脚本语言,编译以后只有一百余K,用C语言开发并且是开源的,设计目的是嵌入应用程序为应用程序提供灵活的扩展和定制功能,说白了就是做外挂,市面上90%的外挂都是用Lua脚本实现的;除了做外挂还可以反外挂
Lua基础语法
演示用的Eclipse的LDT客户端,直接从网址https://eclipse.dev/ldt/下载客户端Stable release (1.4.2),不使用eclipse插件,安装插件比较麻烦,以后mark
基础语法没讲完,涵盖Lua程序百分之七八十的内容,以后系统学;以下内容组合也能写出比较复杂的Lua程序
使用LDT创建Lua项目
创建新Lua项目

设置项目名称和Luajit版本
🔎:项目名称随意,版本使用默认的5.1即可
main函数
Lua中的main函数对应Java中的main方法
main方法定义示例
这也是定义函数的方法,local是作用域,function表示这是一个函数,main是函数名,括号中可以接参数,括号到end间的区域就是写代码的地方
🔎:lua的代码块不像java一样使用花括号来表示一个代码块的结束,也不像Python一样使用严格的缩进对齐方式来表示代码片段等级,而是通过特定的关键字开启代码块,以关键字end作为代码块的结束,如果没有end代码块就不知道在何处被结束
最下面的
main()是去调用上面定义的main方法在LDT中运行Lua脚本点击绿色的运行按钮--run as--lua Application
xxxxxxxxxxlocal function main()endmain()
关键字
关键字不能在Lua脚本中用作变量名
关键字列表
nil是空值,表示访问的是一个没有声明过的变量,相当于java和c语言中的NULL
and break do else elseif end false for function if in local nil not or repeat return then true until while
变量
Lua中的变量分为全局变量和局部变量,
作用域
变量声明前加local关键字是局部变量如
local a=5🔎:局部变量只能在代码块内部进行使用
变量声明前没有任何特殊说明全是全局变量如
a=5🔎:函数或者语句块中的定义的变量没有local关键字都是全局变量,可以在任何地方进行调用
变量赋值
可以多个变量同时赋值,根据顺序进行匹配
数量对不上也不会报错,多出来的字面值不会用上;
字面值少了多出来的参数会赋值控制nil
xxxxxxxxxxname,age,isGay = "yiming", 37, false, "yimingl@hotmail.com"print(name,age,isGay)
注释
单行注释
xxxxxxxxxx--两个减号是单行注释多行注释
xxxxxxxxxx--[[多行注释,可以换行]]
数据类型
Lua的基本数据类型很少,只有字符串和基本的64位的double数字类型,在lua内部会帮我们自动转型
数字
数字类型变量定义示例
数字变量直接写数字,不用写具体类型,Lua语法中的变量都是弱类型的,只有执行的时候才知道数字是那种类型的
【数字类型实例】
xxxxxxxxxxnum = 1024num = 3.0num = 3.1416num = 314.16e-2num = 0.31416E1num = 0xffnum = 0x56
字符串
字符串类型变量定义示例
字符串字面值可以用单引号,也可以用双引号,还可以使用两个中括号
🔎:两个中括号的字符串可以是多行字符串,而且貌似里面的特殊符号不需要转义
字符串中可以使用转义字符
\n【换行】、\r【回车】、\t【横向制表】、\v【纵向制表】、\\【反斜杠】、\”【双引号】、 以及\'【单引号】等等lua拼接字符串和变量需要在变量前面使用
..,java是在变量两边用+号
【字符串类型实例】
xxxxxxxxxxa = 'alo\n123"'a = "alo\n123\""a = '\97lo\10\04923"'a = [[alo123"]]【字符串可以带换行效果】

布尔类型
布尔类型
false可以用
false和nil表示true可以使用数字
0和空字符串'\0'表示
Table
Table类型定义示例
Table就像java中使用的map,即key-value的形式存储数据
dog就是一个Table,并不是一个Map,因为Table中除了键值对还能放一些额外的东西【感觉Table有点像对象,但是Lua不支持面向对象,只能通过Table模拟出来看起来好像是面向对象的方式】,dog也能直接打印【打印的是Table的内存地址,没有toString()】dog中可以通过key获取到值并给对应的key赋值或者获取更改Table中的值
xxxxxxxxxxlocal function main()dog = {name='111',age=18,height=165.5}dog.age=35print(dog.name,dog.age,dog.height)print(dog)endmain()
数组
数组类型定义和使用示例
数组只有value,没有key;依靠下标去取value;数组的value还可以是自定义函数,而且还是匿名的【牛皮】;而且匿名函数只会在取value并以方法调用的方式才会执行。
arr[4]可以看做匿名函数的方法名数组的下标是从1开始的【Lua的下标都是从1开始】
xxxxxxxxxxlocal function main()arr = {"string", 100, "dog",function() print("wangwang!") return 1 end}print(arr[4]())endmain()数组遍历
使用
for k,v in pairs(数组变量) do函数可以将数组拆成key-value的形式,k是下标,v是对应下标的值;每次循环是按顺序取值并赋值给k,v
xxxxxxxxxxarr = {"string", 100, "dog",function() print("wangwang!") return 1 end}for k, v in pairs(arr) doprint(k, v)endend
流程控制
流程控制对应就是Java中的条件语句
语法格式
🔎:注意布尔表达式两边不用加小括号
xxxxxxxxxxif(布尔表达式1)then--[ 在布尔表达式1为 true 时执行的语句 --]elseif(布尔表达式2)then--[ 在布尔表达式2为 true 时执行的语句 --]elseif(布尔表达式3)then--[ 在布尔表达式3为 true 时执行的语句 --]--[ 还有多个分支继续使用elseif...then扩展 --]else--[ 在上诉所有布尔表达式都为 false 时执行的语句 --]end代码示例
定义一个年龄140,性别男;
如果年龄为40且性别为男则打印
男人四十一枝花【很多脚本语言的逻辑判断都是if...then,then后面是匹配上条件以后执行的代码,且C语言系的if后面要加括号,VBScript这一系的if后面不需要加括号】;中间的其他逻辑判断选项使用
elseif...then连接,相当于java中的else if;【~=意思是不等于】最后总的兜底逻辑判断用else衔接;【lua拼接字符串和变量需要在变量前面使用
..,java是在变量两边用+号】循环体的最后用end结束
xxxxxxxxxxlocal function main()local age = 140local sex = 'Male'if age == 40 and sex =="Male" thenprint(" 男人四十一枝花 ")elseif age > 60 and sex ~="Female" thenprint("old man!!")elseif age < 20 thenio.write("too young, too simple!\n")elseprint("Your age is "..age)endend-- 调用main()
函数
打印函数
print(String),print(name,bol)print函数是Lua的内置函数,向终端控制台打印字符串,是换行打印;如果用逗号隔开是打印两个变量值,用制表符【不像空格,比空格宽很多】隔开
循环
while循环
定义局部变量
i为0,局部变量max为10,当i小于等于10时执行打印i并让i加1end是循环体的end,和函数的end不是同一个end
xxxxxxxxxxlocal i = 0local max = 10while i <= max doprint(i)i = i +1endfor循环
语法格式:
🔎:变量
var从exp1变化到exp2,每次变化以exp3为步长递增var,并执行一次 "执行体"。exp3是可选的,如果不指定,默认为1
xxxxxxxxxxfor var=exp1,exp2,exp3 do<执行体>end代码示例:
🔎:
i初始值为100,想要i<1,每次循环i每次减去2;i = 1, 100, 2表示i等于1,i小于100,每次循环i加上2
xxxxxxxxxxsum = 0for i = 100, 1, -2 dosum = sum + iendprint(sum)
自定义函数
自定义函数示例
定义一个名为myPower的函数,下面的演示是在main函数中又定义了一个myPower函数,作用是两个参量之和,后面调用函数并传参,将结果传递给变量power2并打印
函数可以嵌套定义
千万别把最后的
main()漏了,不然程序压根不会执行
xxxxxxxxxxlocal function main()function myPower(x,y)return y+xendpower2 = myPower(2,3)print(power2)endmain()
匿名函数
匿名函数示例
在下面的函数
newCounter()中定义匿名函数【匿名函数没有名字】,newCounter()返回的是匿名函数,匿名函数的第一次执行结果其实就是1,这种写法类似于javaScript中的闭包,c1是获取匿名函数【本次获取不会进行一次计算,只会为匿名函数的变量赋初始值,这个变量初始值作为全局变量会累加,此时只是执行匿名函数,并没有执行
local i = 0】,此后的c1()会执行匿名函数并且将结果返回,其中匿名函数的变量i累加1;执行一次就会累加一次【理解成执行c1 = newCounter()就将newCounter()返回的匿名函数以c1作为方法名了,匿名函数中的变量i是c1函数中完全独立的变量【看做是完全独立的变量】,又是全局变量且没有初始化动作,所以每次执行都会累加】
xxxxxxxxxxfunction newCounter()local i = 0return function() -- anonymous functioni = i + 1print('i为'..i)return iendendc1 = newCounter()print(c1()) --> 1print(c1()) --> 2print(c1())【执行效果】

成员函数
成员函数示例
person是一个Table,可以在Table中自定义没有的方法,通过
Table名.函数名()对成员函数进行调用
xxxxxxxxxxlocal function main()person = {name='旺财',age = 18}function person.eat(food)print(person.name .." eating "..food)endperson.eat("骨头")endmain()
函数返回值
函数返回值
就是return的值可以return两个甚至多个值,java就不行,需要搞到集合、数组或者对象里面返回,在拉出来分割
xxxxxxxxxxfunction isMyGirl(name)--这里返回的是两个参数,一个是判断name和'xiao6'是否相等的布尔值、一个是传递name变量的值return name == 'xiao6' , nameend--按照变量赋值的规则获取isMyGirl函数的多个返回值并赋值给bol和name变量local bol,name = isMyGirl('xiao6')print(name,bol)
Redis中使用Lua
Lua可以使用其宿主语言C语言或者C++的类库,像游戏或者Redis就是用相应的宿主语言实现的,Lua就可以很方面地去使用这些应用程序的类库,Redis主动为Lua脚本提供了支持,向Lua暴露部分Redis内部的类库,用户无需再安装Lua环境,只需要使用Redis的指令
EVAL script numkeys key [key...] arg [arg...]来直接执行Lua即可,该指令中script就是Lua脚本,numkeys表示可以向Lua脚本中传递参数,[key...]是KEYS列表,[arg...]是ARGV列表🔎:使用Lua脚本能保证Redis命令操作的原因是Lua脚本是被一次性发送多个打包好的指令给Redis,因为redis是单线程的,执行指令需要按顺序一条一条执行,只要保证打包好的指令是原子性的上传给Redis,就能保证一批指令执行的原子性
EVAL指令
EVAL script numkeys key [key...] arg [arg...]指令详解参数
script:Lua脚本字符串,该脚本应该被处理成不带格式的一行参数
numkeys:KEYS列表的元素个数🔎:该参数在EVAL指令中必须传递,否则报错
参数
[key...]:KEYS列表,元素以空格进行分隔,在参数script中通过参数KEYS[下标]获取,下标从1开始参数
[arg...]:ARGV列表,元素以空格进行分隔,在参数script中通过参数ARGV[下标]获取,下标从1开始
EVAL指令使用注意事项
使用EVAL指令必须传递
numkeys的值,即KEYS列表的数量🔎:如果完全不传递
numkeys执行EVAL指令就会直接报错(error) ERR wrong number of arguments for 'eval' command
xxxxxxxxxx[root@nginx2 ~]# redis-cli127.0.0.1:6379> EVAL "print('hello world!')"(error) ERR wrong number of arguments for 'eval' commandRedis中的Lua脚本,控制台不会输出脚本的打印指令print函数中的值,而是输出Lua脚本return的返回值
🔎:没有返回值会直接输出nil,有返回值即使没有print函数也会直接在控制台打印返回值
xxxxxxxxxx127.0.0.1:6379> EVAL "print('hello world!')" 0(nil)127.0.0.1:6379> EVAL "return 'hello world!'" 0"hello world!"Redis不允许用户去声明全局的lua脚本变量,只允许声明局部变量
xxxxxxxxxx127.0.0.1:6379> EVAL "a=0 return a" 0(error) ERR Error running script (call to f_35023021fa0eb771c5e9df622d1df11d3141169e): @user_script:1: user_script:1: Attempt to modify a readonly table在Eval指令中使用流程控制语句
xxxxxxxxxx127.0.0.1:6379> EVAL "if 10>20 then return 10 else return 20 end" 0(integer) 20在EVAL指令中通过
key列表和arg列表向流程控制语句传递参数,示例如下🔎:
numkeys用于指定KEYS列表中元素的个数,比如numkeys的值为2,表示后面指令的参数前2个是KEYS列表,后面的都是ARGV列表,列表中的元素通过列表名[下标]进行引用,两个列表的下标都是从1开始的🔎:KEYS列表和ARGV列表中的参数无需全部是使用,不使用也不会报错
🔎:下面示例的含义是如果KEYS列表的第一个元素大于ARGV列表的第一个元素就返回KEYS列表的第二个元素,否则就返回ARGV列表的第二个元素
xxxxxxxxxx127.0.0.1:6379> EVAL "if KEYS[1]>ARGV[1] then return KEYS[2] else return ARGV[2] end" 2 10 20 30 40"40"在EVAL指令中返回多个参数值
🔎:注意EVAL指令中只有用花括号括起来的多个值才能被全部打印,没有花括号括起来的值只会打印第一个
xxxxxxxxxx127.0.0.1:6379> EVAL "return {10,20,30,40}" 01) (integer) 102) (integer) 203) (integer) 304) (integer) 40127.0.0.1:6379> EVAL "return 10,20,30,40" 0(integer) 10127.0.0.1:6379> EVAL "return {KEYS[1],KEYS[2],ARGV[1],ARGV[2]}" 4 10 20 30 40 50 60 70 80 901) "10"2) "20"3) "50"4) "60"
EVAL指令中的Lua脚本使用redis指令
🔎:lua脚本可以保证Redis多条指令原子性的原理是Redis客户端程序通过lua脚本把多个Redis指令一次性发送给Redis服务器,那么这些指令就不会被其他客户端指令打断。Redis的单线程设计也会保证脚本以原子性的方式执行即当某个脚本正在运行的时候,不会有其他脚本或Redis命令被执行。
要在参数
script的lua脚本中使用redis命令需要在lua脚本中调用Redis主动向Lua脚本暴露的一个类库redis的call方法来执行redis中的指令,相应的格式为EVAL "redis.call('get','<key>')" 0xxxxxxxxxx127.0.0.1:6379> set lock 123-321-456OK127.0.0.1:6379> EVAL "return redis.call('get','lock')" 0"123-321-456"lua脚本中的所有redis指令都通过
redis.call()进行调用,call方法中的参数和redis的实际指令是完全一样的顺序,用逗号填充redis命令中间的空格就是对应的call方法参数列表,如xxxxxxxxxx127.0.0.1:6379> EVAL "return redis.call('get','lock')" 0"-430322"127.0.0.1:6379> EVAL "return redis.call('set','lock','123123-232132-321313','ex',150)" 0OK127.0.0.1:6379> EVAL "return redis.call('get','lock')" 0"123123-232132-321313"127.0.0.1:6379> EVAL "return redis.call('ttl','lock')" 0(integer) 139在lua中使用redis指令一般都是嵌入到应用程序中做复杂业务比如实现分布式锁,此时key和value以及命令参数都是变量,此时就可以配合KEYS列表和ARVG列表来动态地传递redis命令的参数
xxxxxxxxxx127.0.0.1:6379> EVAL "return redis.call(KEYS[1],KEYS[2],KEYS[3])" 3 'set' 'lock' '1232141321-23213-32131'OK127.0.0.1:6379> EVAL "return redis.call('get','lock')" 0"1232141321-23213-32131"
EVAL指令中使用Lua脚本来保证多个redis命令的原子性
这个是配合基于Redis实现的分布式锁最终解锁时通过lua脚本来保证验证键值对的value值与获取锁设置的value值一致并在一致的情况下删除键值对释放锁两个操作的原子性的代码
🔎:当redis中没有对应value为
12345678,key为lock的键值对时就直接返回0,如果有就删除对应的键值对,del命令删除成功会自动返回1,删除失败返回0🔎:经过测试,该lua脚本没有问题;只有当key和value都为指定值时才删除对应键值对并返回1,当对应key的键值对不存在或者键值对存在但是value值不是指定值,就直接返回0
xxxxxxxxxx127.0.0.1:6379> get lock(nil)127.0.0.1:6379> EVAL "if redis.call('get',KEYS[1]) == ARGV[1] then return redis.call('del',KEYS[1]) else return 0 end" 1 'lock' '12345678'(integer) 0127.0.0.1:6379> set 'lock' '12345678'OK127.0.0.1:6379> EVAL "if redis.call('get',KEYS[1]) == ARGV[1] then return redis.call('del',KEYS[1]) else return 0 end" 1 'lock' '12345678'(integer) 1127.0.0.1:6379> get lock(nil)127.0.0.1:6379> set 'lock' '8765431'OK127.0.0.1:6379> get lock"8765431"127.0.0.1:6379> EVAL "if redis.call('get',KEYS[1]) == ARGV[1] then return redis.call('del',KEYS[1]) else return 0 end" 1 'lock' '12345678'(integer) 0
基于Redis的分布式锁
基于Redis中的
set <key> <value> [Ex seconds] [Px milliseconds] [NX|XX]、lua脚本和乐观锁逻辑实现的分布式锁
比较完善的基于Redis的分布式锁实现如下
分布式锁
DistributedRedisLockxxxxxxxxxxpublic class DistributedRedisLock implements Lock {private StringRedisTemplate redisTemplate;private String lockName;private String hashField;private long expire = 30;public DistributedRedisLock(StringRedisTemplate redisTemplate, String lockName, String uuid) {this.redisTemplate = redisTemplate;this.lockName = lockName;this.hashField = uuid + ":" + Thread.currentThread().getId();}public void lock() {this.tryLock();}public void lockInterruptibly() throws InterruptedException {}//无参tryLock方法是使用默认有效时间30s作为锁的有效时间public boolean tryLock() {try {return this.tryLock(-1L, TimeUnit.SECONDS);} catch (InterruptedException e) {e.printStackTrace();}return false;}/*** 加锁方法* @param time* @param unit* @return* @throws InterruptedException*/public boolean tryLock(long time, TimeUnit unit) throws InterruptedException {if (time != -1){this.expire = unit.toSeconds(time);}String script = "if redis.call('exists', KEYS[1]) == 0 or redis.call('hexists', KEYS[1], ARGV[1]) == 1 " +"then " +" redis.call('hincrby', KEYS[1], ARGV[1], 1) " +" redis.call('expire', KEYS[1], ARGV[2]) " +" return 1 " +"else " +" return 0 " +"end";while (!this.redisTemplate.execute(new DefaultRedisScript<>(script, Boolean.class), Arrays.asList(lockName), hashField, String.valueOf(expire))){Thread.sleep(50);}// 加锁成功,返回之前,开启定时器自动续期this.renewExpire();return true;}/*** 解锁方法*/public void unlock() {String script = "if redis.call('hexists', KEYS[1], ARGV[1]) == 0 " +"then " +" return nil " +"elseif redis.call('hincrby', KEYS[1], ARGV[1], -1) == 0 " +"then " +" return redis.call('del', KEYS[1]) " +"else " +" return 0 " +"end";Long flag = this.redisTemplate.execute(new DefaultRedisScript<>(script, Long.class), Arrays.asList(lockName), hashField);if (flag == null){throw new IllegalMonitorStateException("this lock doesn't belong to you!");}}public Condition newCondition() {return null;}//锁自动续期private void renewExpire(){String script = "if redis.call('hexists', KEYS[1], ARGV[1]) == 1 " +"then " +" return redis.call('expire', KEYS[1], ARGV[2]) " +"else " +" return 0 " +"end";new Timer().schedule(new TimerTask() {public void run() {if (redisTemplate.execute(new DefaultRedisScript<>(script, Boolean.class), Arrays.asList(lockName), hashField, String.valueOf(expire))) {renewExpire();}}}, this.expire * 1000 / 3);}}工厂方法获取分布式锁对象
xxxxxxxxxxpublic class DistributedLockClient {private StringRedisTemplate redisTemplate;private String uuid;public DistributedLockClient() {this.uuid = UUID.randomUUID().toString();}public DistributedRedisLock getRedisLock(String lockName){return new DistributedRedisLock(redisTemplate, lockName, uuid);}}业务方法使用分布式锁示例
业务逻辑是并发请求对100个用户线程,1s内每个用户线程发起50次扣减库存请求,总共发起5000次,操作虚拟机上的同一个Redis数据库的同一个共享数据,对库存数量5000进行单次扣减1,累计5000次扣减请求,使用基于Redis的分布式锁解决Redis中共享库存数据的并发线程安全问题
xxxxxxxxxxpublic void deduct() {DistributedRedisLock redisLock = this.distributedLockClient.getRedisLock("lock");redisLock.lock();try {// 1. 查询库存信息String stock = redisTemplate.opsForValue().get("stock").toString();// 2. 判断库存是否充足if (stock != null && stock.length() != 0) {Integer st = Integer.valueOf(stock);if (st > 0) {// 3.扣减库存redisTemplate.opsForValue().set("stock", String.valueOf(--st));}}} finally {redisLock.unlock();}}
该分布式锁实现了以下特性
通过Redis的
setnx指令做到分布式锁的独占排他,后面用lua脚本一次提交执行和Redis单线程特性保证原子性并结合lua脚本的逻辑判断替换了setnx指令的独占排他通过设置过期时间来防服务宕机或者意外锁无法释放导致的死锁现象,使用完整的set指令来保证独占排他并同时设置有效时间保证上锁和设置有效时间两步操作的原子性,最后被lua脚本整合到同时实现上锁和锁重入的
hincrby指令和Expire指令中,用Lua脚本保证上锁或锁重入与设置有效时间两步操作的原子性通过Redis中的Hash数据类型,以key作为锁的唯一标识,以key加field字段【当前线程创建的UUID】作为线程自身上锁的唯一标识来防止当前线程误删其他线程上的锁,避免因为锁提前失效或者一系列其他原因导致的非上锁线程执行锁释放操作;后为了在定义方法时就确定同一个线程锁重入的自动识别,uuid很难实现在方法定义时就保证方法锁重入时两把锁的uuid相同,因此将当前线程标识即field字段重新设计为
线程id,为了避免集群环境下不同服务实例的线程id相同导致上锁通过锁重入获取锁导致锁失效问题,使用uuid作为服务的唯一标识,field字段使用uuid:线程id结合key作为区分获取锁的当前线程的唯一标识使用lua脚本保证加锁和设置锁过期时间、判断锁是当前线程上的锁和释放锁、判断锁是当前线程上的锁和为锁续期多步操作的原子性
分布式锁的不可重入也可能会导致死锁,用Hash数据类型,key作为锁唯一标识,key和field【
uuid:线程id】作为当前线程的唯一标识来做锁重入、锁释放和锁续期中锁属于当前线程的判断标识、以value作为锁重入次数的计数,该设计模仿可重入锁的锁重入实现方式,用lua脚本保证检查锁和操作锁多步操作的原子性使用JDK的Timer定时器和lua脚本实现可重入锁的自动续期
Nginx中使用Lua
OpenResty
OpenResty做Nginx的二次开发,需要深入学习Lua语言,熟悉OpenResty相关的API,甚至需要去看Nginx和OpenResty的源代码才能写出高效的程序,有很多开源项目已经将这些程序用Lua写出来了,比如比较流行的网关Kong等
新版本的OpenResty默认使用Luajit作为默认的编译器,不需要再额外安装Luajit了,在OpenResty的安装目录
/usr/local/openresty下能看到如下目录结构相比于nginx多了几个目录,Luajit是编译器;lualib中有很多OpenResty开发的包,
/lualib/resty目录中有和dns、lrucache、limit、redis连接、mysql连接和一些哈希算法相关的包【这些都是Nginx中没有的,可以借助这些包做一些开发】;lua这些代码在使用的使用不需要像Nginx加载c语言写的模块需要load或者编译在运行程序中,可以通过动态引用来进行使用【可以理解为明文的脚本代码,需要的时候把代码跑一下】;OpenResty其实就是Nginx,在原有的Nginx上添加了Luajit和其他的功能
xxxxxxxxxx[root@nginx1 openresty]# lsbin COPYRIGHT luajit lualib nginx pod resty.index site
Lua脚本的使用
在OpenResty中使用lua脚本
🔎:lua脚本写在Nginx的配置文件中
使用方式一
在nginx.conf中添加一个location写lua脚本,location中除了lua就没有其他东西了,没有proxy_pass或者root根目录,全是由Lua代码负责输出内容
🔎:这种方式存在一个弊端,因为配置文件主要是做配置用的,不是拿来做编程用的;一旦lua代码多了,配置文件会非常庞大,这就引申出第二种方式在配置文件nginx.conf中引入Lua脚本
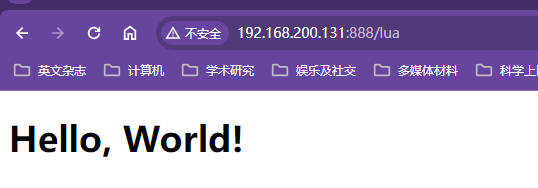
xxxxxxxxxxserver {listen 888;server_name localhost;#charset koi8-r;#access_log logs/host.access.log main;#以下这段lua代码在OpenResty的初始化配置中就已经有了location /lua {#意思是返回的内容以html的形式展现出来,其实就是添加响应头Content-Type让浏览器识别直接下载不要展示default_type text/html;#content_by_lua就表示lua开始执行参与请求处理了,lua的内容在引号之间#函数ngx.say是在nginx中输出参数内容,这里的参数内容是字符串content_by_lua 'ngx.say("<p>Hello, World!</p>")';}location / {root html;index index.html index.htm;}error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}测试效果
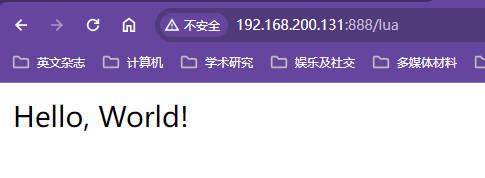
使用方式二
在nginx.conf的location下使用命令
content_by_lua_file lua脚本的相对或绝对路径;引入lua脚本,Lua脚本的根目录在nginx的主目录下操作步骤:
在nginx的根目录下创建lua目录,在lua目录下创建lua脚本文件
hello.lua,向脚本文件中写入以下内容【hello.lua】
xxxxxxxxxxngx.say("<p>Hello, World!!!</p>")修改配置文件
nginx.conf,将原来lua脚本直接写入配置文件的站点目录改为在站点目录中引入lua脚本🔎:经过测试,因为期间lua脚本的相对路径写错了,导致页面不展示,更改以后正常展示,由此证明实现了相应的效果
🔎:注意因为还是在配置文件中引入了lua脚本,所以更改了lua脚本还是需要重启Nginx
xxxxxxxxxxserver {listen 888;server_name localhost;location /lua {default_type text/html;content_by_lua_file lua/hello.lua;}location / {root html;index index.html index.htm;}error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}
测试效果
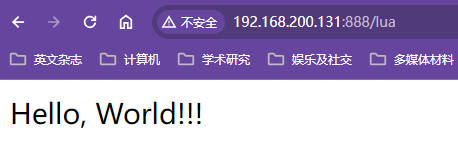
开启lua脚本热部署
因为每次修改lua脚本以后都需要重启nginx,很不方便,在http模块下使用命令
lua_code_cache off;来开启lua脚本的热部署🔎:这个热部署生产环境不要开,对性能影响比较大;
🔎:设置该指令后关闭nginx会提示
nginx: [alert] lua_code_cache is off; this will hurt performance in /usr/local/openresty/nginx/conf/nginx.conf:13,意思是设置该指令会损伤nginx的性能;这是因为lua在OpenResty中去跑是介于脚本语言和静态编译语言之间的动态语言,性能比较高,但是如果编程纯粹的脚本语言或者解释型语言,每次请求的时候都会去重新加载执行一遍,浪费性能【没听懂,以后理解】;但是开发的时候方便程序员去重启nginx🔎:这个热部署只是针对lua脚本文件修改,修改了主配置文件还是需要重启nginx
xxxxxxxxxxworker_processes 1;events {worker_connections 1024;}http {include mime.types;default_type application/octet-stream;#以下命令是开启lua脚本的热部署,关闭以后修改lua脚本就不需要再重启nginx了lua_code_cache off;sendfile on;keepalive_timeout 65;server {listen 888;server_name localhost;location /lua {default_type text/html;content_by_lua_file lua/hello.lua;}location / {root html;index index.html index.htm;}error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}}
Lua脚本获取系统变量
获取请求的变量并在通过lua对变量进行加工,有这些请求参数和信息就可以针对这些信息使用lua做一些额外的开发
Lua获取请求头信息
local headers = ngx.req.get_headers():获取当前请求的头信息headers["Host"]:请求的ip和端口,key不区分大小写headers["user-agent"]:请求的客户端信息【也可以通过headers.user_agent获取对应的属性值】脚本
hello.luaxxxxxxxxxxlocal headers = ngx.req.get_headers()ngx.say("Host : ", headers["Host"], "<br/>")ngx.say("user-agent : ", headers["user-agent"], "<br/>")ngx.say("user-agent : ", headers.user_agent, "<br/>")for k,v in pairs(headers) doif type(v) == "table" thenngx.say(k, " : ", table.concat(v, ","), "<br/>")elsengx.say(k, " : ", v, "<br/>")endend执行效果
🔎:实际上headers中的所有参数从第4行到11行一共八个参数
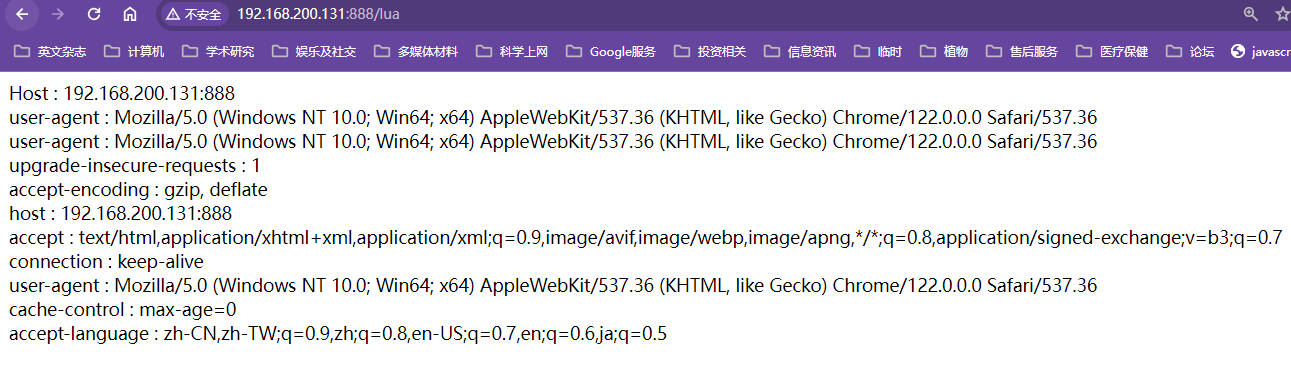
lua处理Http请求的其他方式
🔎:没说怎么用,只是说除了
content_by_lua_file还可以使用以下命令修改系统变量,猜测是和content_by_lua_file一样使用在location中set_by_lua参数解析:修改nginx中的系统变量
rewrite_by_lua
参数解析:修改nginx中的uri
access_by_lua参数解析:访问控制
header_filter_by_lua参数解析:修改响应头
boy_filter_by_lua参数解析:修改响应体
log_by_lua参数解析:日志交互
Lua获取Post请求的请求参数
hello.lua🔎:核心还是通过
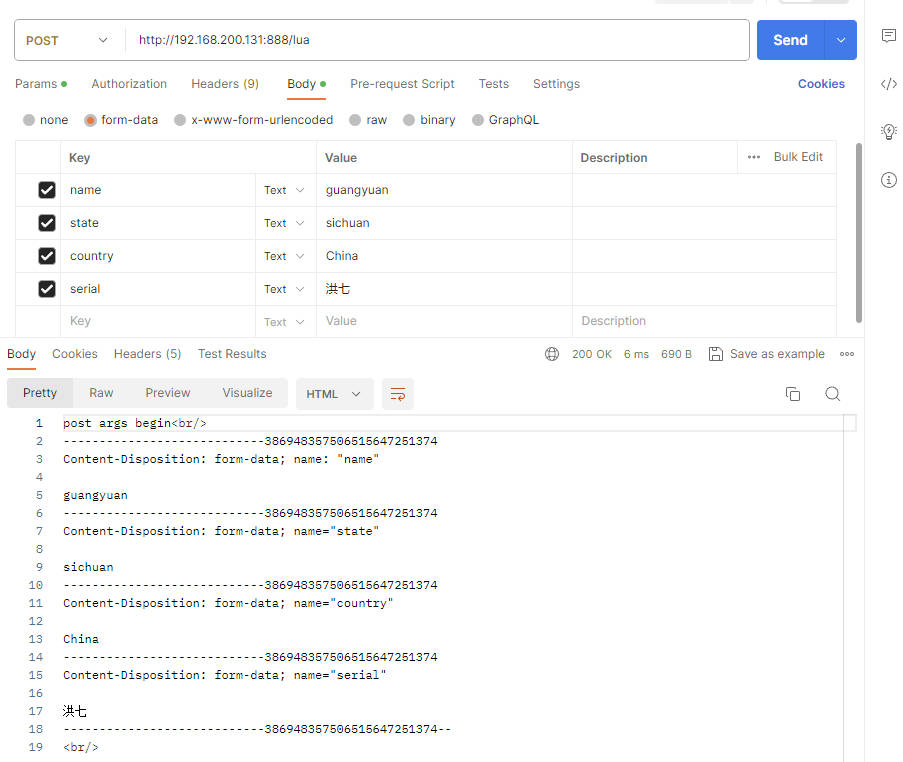
local post_args = ngx.req.get_post_args()获取到Post请求的请求参数列表然后对请求参数列表进行遍历xxxxxxxxxxngx.req.read_body()ngx.say("post args begin", "<br/>")local post_args = ngx.req.get_post_args()for k, v in pairs(post_args) doif type(v) == "table" thenngx.say(k, " : ", table.concat(v, ", "), "<br/>")elsengx.say(k, ": ", v, "<br/>")endend执行效果
🔎:这个需要发送post请求才能看见效果,get请求参数列表为空,但是不会报错,使用postman进行测试,注意参数要放在请求体中的表单去提交
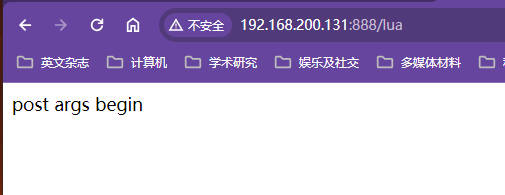
postman请求参数设置
Lua获取uri中的单一变量
nginx.conf
xxxxxxxxxxlocation /nginx_var {default_type text/html;content_by_lua_block {ngx.say(ngx.var.arg_a)}}
Lua获取请求uri中的所有变量
hello.luaxxxxxxxxxxlocal uri_args = ngx.req.get_uri_args()for k, v in pairs(uri_args) doif type(v) == "table" thenngx.say(k, " : ", table.concat(v, ", "), "<br/>")elsengx.say(k, ": ", v, "<br/>")endend
Lua获取请求的通用信息
🔎:以下代码全部在hello.lua脚本中
获取http协议版本
ngx.req.http_version()xxxxxxxxxxngx.say("ngx.req.http_version : ", ngx.req.http_version(), "<br/>")获取请求的方法
ngx.req.get_method()xxxxxxxxxxngx.say("ngx.req.get_method : ", ngx.req.get_method(), "<br/>")获取原始的请求头内容
ngx.req.raw_header()🔎:最原始的整个请求头文本
xxxxxxxxxxngx.say("ngx.req.raw_header : ", ngx.req.raw_header(), "<br/>")获取请求的请求体内容
ngx.req.get_body_data()xxxxxxxxxxngx.say("ngx.req.get_body_data() : ", ngx.req.get_body_data(), "<br/>")
Lua做Nginx进程缓存
OpenResty提供两种方式去Nginx内存中操作缓存数据,促进提高系统的并发量承载能力,方式一是使用
shared_dict,方式二是使用lua-resty-lrucache模块做内存缓存此前nginx做内存缓存只能缓存一些文件句柄或者静态资源文件索引列表,或者IP并发列表、IP的QPS数据,现在通过OpenResty的进程缓存空间能够缓存自定义数据,一般也是存储少量的数据,比如计数等数据,不会存储内容很大的数据;一方面是内存容易被撑爆,第二是类似于
shared_dict这种字典式的内存存储在修改数据的时候会有锁的产生,对内存中响应数据的QPS有影响
方式一:在lua脚本中使用
lua_shared_dict🔎:
shared_dict性能比较高效,在多个worker进程中可以去共享一份缓存数据,因为多进程操作一份缓存数据,一定会涉及到锁的产生,有点像在nginx中跑一个小型的redis核心一:在lua脚本中使用变量
shared_data = ngx.shared.shared_data来操纵缓存数据核心二:同时使用
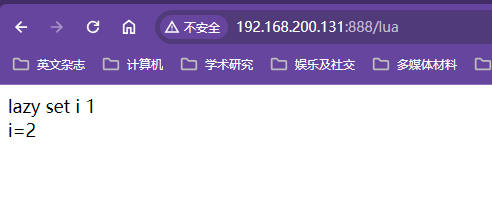
shared_dict需要在主配置文件的http模块中声明shared_dict和其大小hello.luaxxxxxxxxxx--操作shared_dict的缓存数据需要获取到shared_data对象local shared_data = ngx.shared.shared_data--从shared_dict的缓存数据中通过key为i获取对应的值local i = shared_data:get("i")--如果i没有数据那么将i设置为1if not i theni = 1--向shared_dict的缓存数据中通过set方法向缓存空间设置key为i的数据的值为i的值shared_data:set("i", i)--打印向缓存空间内设置了i-1这个键值对数据ngx.say("lazy set i ", i, "<br/>")end--如果之前已经有了对应i的数据,对应缓存空间中i的数据再自加1,并将结果取出赋值给ii = shared_data:incr("i", 1)--打印当前缓存空间中key为i的数据的值ngx.say("i=", i, "<br/>")nginx.conf
🔎:声明shared_dict的空间大小,表示申请1M内存去做进程间的内存缓存,该内存缓存能够被所有的worker进程进行访问并且能保证原子性
xxxxxxxxxxworker_processes 1;events {worker_connections 1024;}http {include mime.types;default_type application/octet-stream;#声明shared_dict的空间大小,表示申请1M内存去做进程间的内存缓存,该内存缓存能够被所有的worker进程进行访问并且能保证原子性lua_shared_dict shared_data 1m;lua_code_cache off;sendfile on;keepalive_timeout 65;server {listen 888;server_name localhost;location /lua {default_type text/html;content_by_lua_file lua/hello.lua;}location / {root html;index index.html index.htm;}error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}}请求访问效果
🔎:这是从缓存空间取出的数据,中间还涉及到使用Lua代码对key为i的数据的创建和自增操作
方式二:使用
lua-resty-lrucache模块做内存缓存LRU缓存对比
shared_dict的功能更加强大一些,该模块纯粹用Lua语言实现的,由Lua官方提供的模块,也可以像shared_dict一样在nginx的内存中使用缓存,且运行在独立的进程中,单进程的增删改操作不需要添加锁,做一些修改操作的时候性能会更高一些,但是一般使用时不会感觉和shared_dict在性能上的差异🔎:性能上的差异并不是很大,差别就在一个有锁,一个没有锁
🔎:LRU的Git仓库和官方文档:https://github.com/openresty/lua-resty-lrucache
LRU缓存可以额外做LRU算法上的清理工作;同时LRU缓存是以
key-value的数量个数作为大小的限制、shared_dict是以缓存空间的内存占用大小来作为限制,shared_dict能更有效地控制系统内存缓存空间的大小占用,LRU没法预估内存缓存空间的大小,这种大小的限制需要对每一个key-value的大小需要提前预测感知才行,但是内存也更加弹性化,不会导致因为内存空间占满了导致数据写不进去lua-resty-lrucache默认就已经在OpenResty的目录下了,资源文件路径/usr/local/openresty/lualib/resty/lrucache.luaLRU缓存使用时一定要关闭lua脚本的热部署,即不能使用
lua_code_cache off;,默认是on官方推荐的用法是在lua脚本中自定义函数来使用,使用示例如下
🔎:一定要保证初始化操作只能被执行一次,包括连接mysql和redis的数据库连接池时也是一样只能执行一次,否则是用不上此前使用过的连接或者缓存空间的,
Lua如何保证只执行一次某个代码片段没有讲,这里后续自己学习【还没讲呢,这里第一次演示的就是每次请求都执行一次初始化代码的情况】【实际上这里的代码确实只会执行一次,这个也是全局变量,但是因为在主配置文件开启了lua脚本的热部署,lua_code_cache off;关闭了lua代码的缓存,每次请求结束lua代码创建的全局参数缓存都会不使用】
cache.lua🔎:该文件在
/usr/local/openresty/lualib/my/cache.lua
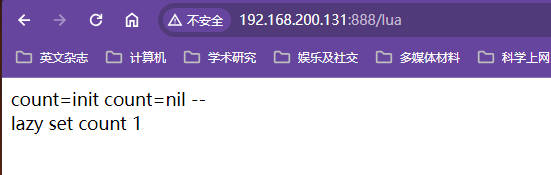
xxxxxxxxxx--定义一个数组local _M = {}local _M = {}--这部分到第一个end之间的代码在lua脚本热部署关闭的情况下只能执行一次,这部分是内存空间初始化的部分,每次请求都执行会导致每次用的缓存空间都是新的,永远在执行第一次的代码。后续请求也无法获取到此前请求存入缓存中的数据;实际上这里的代码确实只会执行一次,这个也是全局变量,但是因为在主配置文件开启了lua脚本的热部署,lua_code_cache off;关闭了lua代码的缓存,每次请求结束lua代码创建的全局参数缓存都会不使用lrucache = require "resty.lrucache"c, err = lrucache.new(200) -- allow up to 200 items in the cache,初始化内存缓存空间,表示能承载200个键值对ngx.say("count=init")--如果c没有被附上值,c没有值为false,not false即为true,即创建缓存空间出现问题就会报错if not c thenerror("failed to create the cache: " .. (err or "unknown"))end--这个是在数组_M中的一个元素定义一个go函数,在这个方法中去向缓存空间操作键值对function _M.go()--从缓存空间中获取key为count的键值对valuecount = c:get("count")--将缓存空间中key为count的键值对的value设置成100,这一步是不是多余了,反正后面都会重新赋值c:set("count",100)--打印最开始从缓存中取出的key为count的value值ngx.say("count=", count, " --<br/>")--如果没有从缓存中获取到对应key为count的value值if not count then--向缓存空间设置键值对count-1c:set("count",1)--打印首次向缓存空间中设置键值对count-1ngx.say("lazy set count ", c:get("count"), "<br/>")else--如果有值直接让值加1并打印没有加1以前的count,即这里的count+1是为了下次请求访问准备获取的值,因为这里目前每次请求都会创建一次缓存空间,所以获取到的count永远是初始化的值1,而且以后得请求都无法拿出上一个请求向缓存中设置的值c:set("count",count+1)ngx.say("count=", count, "<br/>")endendreturn _M在主配置文件
nginx.conf中使用content_by_lua_block来对lua函数进行调用xxxxxxxxxxworker_processes 1;events {worker_connections 1024;}http {include mime.types;default_type application/octet-stream;#声明shared_dict的空间大小,表示申请1M内存去做进程间的内存缓存,该内存缓存能够被所有的worker进程进行访问并且能保证原子性lua_shared_dict shared_data 1m;lua_code_cache off;sendfile on;keepalive_timeout 65;server {listen 888;server_name localhost;location /lua {default_type text/html;#content_by_lua_file lua/hello.lua;#在该代码块中去调用lua脚本中的函数方法,require相当于引入lua的代码文件,这个是有默认根目录的,需要在日志文件看报错信息来找到对应的根目录位置,貌似在引入的时候执行了一次对应的代码块,这个引入似乎不像content_by_lua_file一样每个请求都会执行一次,而是后续只去调用其中返回的数组的go函数,开启了lua_code_cache off;会导致引入的代码执行产生的对象无法被缓存,content_by_lua_block {require("my/cache").go()}}location / {root html;index index.html index.htm;}error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}}require引入脚本文件不存在的位置报错提示信息🔎:这里找文件my/cache,通过访问
/lua站点,因为没有该文件,错误日志会显示在所有可能目录中没有对应的文件默认的lua文件可以存在的地方的根目录如下所示,
lualib也是一个根目录
xxxxxxxxxx2024/01/13 18:15:39 [error] 45316#0: *1 lua entry thread aborted: runtime error: content_by_lua(nginx.conf:30):2: module 'my/cache' not found:no field package.preload['my/cache']no file '/usr/local/openresty/site/lualib/my/cache.ljbc'no file '/usr/local/openresty/site/lualib/my/cache/init.ljbc'no file '/usr/local/openresty/lualib/my/cache.ljbc'no file '/usr/local/openresty/lualib/my/cache/init.ljbc'no file '/usr/local/openresty/site/lualib/my/cache.lua'no file '/usr/local/openresty/site/lualib/my/cache/init.lua'no file '/usr/local/openresty/lualib/my/cache.lua'no file '/usr/local/openresty/lualib/my/cache/init.lua'no file './my/cache.lua'no file '/usr/local/openresty/luajit/share/luajit-2.1.0-beta3/my/cache.lua'no file '/usr/local/share/lua/5.1/my/cache.lua'no file '/usr/local/share/lua/5.1/my/cache/init.lua'no file '/usr/local/openresty/luajit/share/lua/5.1/my/cache.lua'no file '/usr/local/openresty/luajit/share/lua/5.1/my/cache/init.lua'no file '/usr/local/openresty/site/lualib/my/cache.so'no file '/usr/local/openresty/lualib/my/cache.so'no file './my/cache.so'no file '/usr/local/lib/lua/5.1/my/cache.so'no file '/usr/local/openresty/luajit/lib/lua/5.1/my/cache.so'no file '/usr/local/lib/lua/5.1/loadall.so'stack traceback:coroutine 0:[C]: in function 'require'content_by_lua(nginx.conf:30):2: in main chunk, client: 192.168.200.1, server: localhost, request: "GET /lua HTTP/1.1", host: "192.168.200.131:888"更改Lua脚本的根目录
Lua脚本的根目录也可以通过在主配置文件的http模块下通过以下配置设置,这是将lua脚本的目录修改到绝对路径
/path/to/lua-resty-lrucache/lib/下🔎:上面的演示不采用这种方式,选择在lualib目录下创建my目录,在该目录下存放自定义的lua脚本文件
xxxxxxxxxx# nginx.confhttp {# only if not using an official OpenResty releaselua_package_path "/path/to/lua-resty-lrucache/lib/?.lua;;";...}执行效果
🔎:
count=init是文件cache.lua通过代码ngx.say("count=init")打印的日志,通过测试发现目前每次请求都会去执行一次cache.lua文件中的代码,c, err = lrucache.new(200)创建缓存空间的代码后面紧跟的就是打印count=init的代码,每次请求都打印了,说明每次请求都新创建的缓存空间,该问题需要解决,否则缓存空间根本没有办法使用
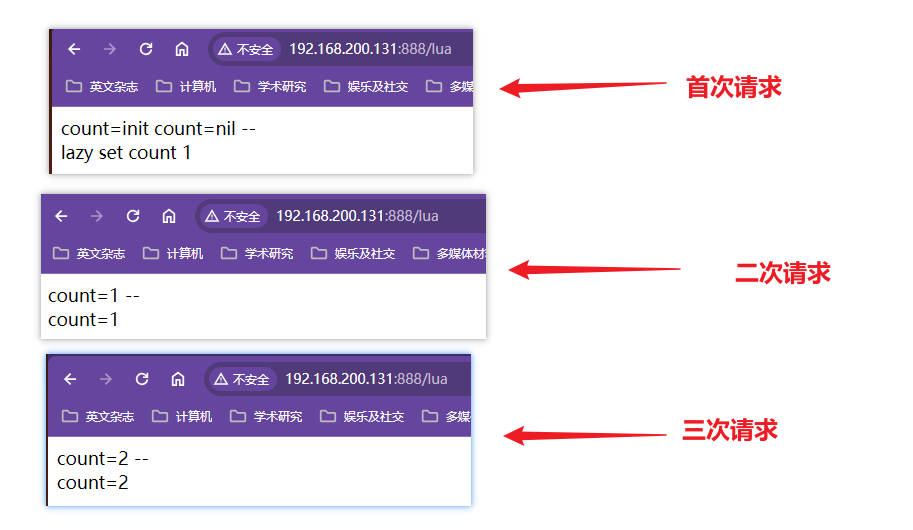
将主配置文件的
lua_code_cache off;注释掉观察多次请求的效果🔎:原因就是
lua_code_cache off;禁用Lua脚本缓存,导致require("my/cache")执行了一次该文件返回的对象无法被缓存,从而每次请求都会去执行一次初始化代码,实际生产环境中不会开启该热部署选项🔎:以下是注释掉该热部署配置后的响应效果
连接Redis
OpenResty连接redis也可以使用两个模块
模块一是此前讲过的开源版本nginx使用
redis2-nginx-module连接外置内存缓存redis🔎:redis2-nginx-module是一个支持 Redis 2.0 协议的 Nginx upstream 模块,它可以让 Nginx 以非阻塞方式直接防问远方的 Redis 服务,同时支持 TCP 协议和 Unix Domain Socket 模式,并且可以启用强大的 Redis 连接池功能
模块二是使用模块
lua-resty-redis访问redis,lua-resty-redis是一个纯粹使用lua脚本实现的redis客户端,同样也是OpenResty出品的,Git仓库和官方文档:https://github.com/openresty/lua-resty-redis🔎:Lua实现的redis客户端后期可以看看源码通过学习官方文档自己进行一些更改,但是c语言实现的redis客户端【这个lua实现的客户端是用来远程连接操纵redis服务器的,类似于redis-cli,不是指用lua写了一个redis,实际还是需要单独安装redis服务器】,绝大多数程序员是没有这个能力去修改的;
redis集群或者nginx集群下的lua连接redis脚本找第三方的工具包来使用,如果redis是集群,就使用
resty-redis-cluster来作为redis客户端完成集群上的数据操作,官方文档:https://github.com/steve0511/resty-redis-cluster没有特殊要求使用
redis2-nginx-module或者lua-resty-redis访问操作redis都可以,节省tomcat服务器响应的过程提高效率🔎:这时候为了数据一致性,一般不会让nginx去写或者修改数据,一般只有计数的需求nginx才可能去操纵redis,比如记录Ip的请求次数;业务数据写一般都是tomcat来进行维护;一定要使用Nginx来写入数据一定要用事务保证缓存和数据库双写的数据一致性
使用OpenResty去连接redis
🔎:好像没有单独引入
lua-resty-redis模块,而是OpenResty默认集成了该工具,通过lua命令local redis = require "resty.redis"使用的创建redis连接的lua脚本文件
/usr/local/openresty/nginx/lua/redis.luaxxxxxxxxxx--通过OpenResty自带的工具包resty.redis创建一个redis局部变量local redis = require "resty.redis"--通过局部变量redis创建一个连接对象red出来local red = redis:new()--连接超时配置,毫秒为单位red:set_timeouts(1000, 1000, 1000) -- 1 sec--设置连接地址,返回两个变量,一个ok。一个errlocal ok, err = red:connect("127.0.0.1", 6379)--如果ok的返回值没有东西,直接报错打印错误信息if not ok thenngx.say("failed to connect: ", err)returnend--如果ok有值,通过连接red向redis中设置键值对dog-an animal,仍然返回两个变量ok和err表示数据操作状态ok, err = red:set("dog", "an animal")--不ok就打印错误信息,ok就打印ok信息,且因为有return不再继续向下执行if not ok thenngx.say("failed to set dog: ", err)returnendngx.say("set result: ", ok)--通过连接red拿着dog这个key去获取对应的value,仍然返回两个返回值,查询结果或者错误信息local res, err = red:get("dog")ngx.say(res)--如果查询结果中没有值就打印错误信息并结束方法的执行if not res thenngx.say("failed to get dog: ", err)returnend--我怀疑这个也不会执行,因为res如果是空值,那么上一个判断也会成立,not res应该也为true,不管,系统学了lua在理解;经过测试,如果redis中没有对应的key,get方法返回的res会是null,但是lua中没有null,0和nil代表false,,所以这里判断没有值res的值为ngx.nullif res == ngx.null thenngx.say("dog not found.")returnendngx.say("dog: ", res)主配置文件
nginx.confxxxxxxxxxxworker_processes 1;events {worker_connections 1024;}http {include mime.types;default_type application/octet-stream;lua_shared_dict shared_data 1m;lua_code_cache off;sendfile on;keepalive_timeout 65;server {listen 888;server_name localhost;location /lua {default_type text/html;#执行连接操作redis的脚本文件content_by_lua_file lua/redis.lua;}location / {root html;index index.html index.htm;}error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}}lua脚本执行效果

连接mysql
OpenResty使用
lua-resty-mysql作为连接Mysql的客户端,可以作为mysql客户端发送各种DML、DDL的SQL,同时支持数据库连接池,使用Nginx连接mysql最好查询条件带参数,因为OpenResty中没有预编译功能,不像jdbc的preparedStatement,有很大的风险,比如sql注入🔎:Git仓库以及官方文档:https://github.com/openresty/lua-resty-mysql
🔎:Nginx连接mysql不是特别理想,因为特别容易将流量直接打到mysql上,大项目最好将nginx和mysql隔离开;小项目无所谓,mysql几十个字段,单条查询结果几百到2k字节间,抗个几千的并发也是没问题的
🔎:该模块nginx官方文档有介绍,除了mysql,还有很多其他组件也可以通过OpenResty进行连接
使用OpenResty连接mysql
创建mysql连接的lua脚本文件
/usr/local/openresty/nginx/lua/mysql.lua🔎:这里需要修改mysql的权限,否则连接会失败;mysql client 命令行输入下列指令设置mysql的权限把连接权限改为任何地址
xxxxxxxxxxuse mysql;update user set host = '%' where user ='root';flush privileges;
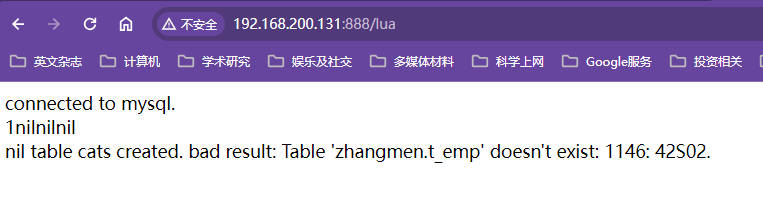
xxxxxxxxxxlocal mysql = require "resty.mysql"local db, err = mysql:new()if not db thenngx.say("failed to instantiate mysql: ", err)returnend--设置连接超时时间1sdb:set_timeout(1000) -- 1 sec--配置数据库的相关信息,连接信息会返回该四个变量local ok, err, errcode, sqlstate = db:connect{host = "192.168.200.131",port = 3306,database = "zhangmen",user = "root",password = "Haworthia0715",charset = "utf8",--mysql返回数据包的最大限制,默认是一兆大小max_packet_size = 1024 * 1024,}ngx.say("connected to mysql.<br>",ok,err,errcode,sqlstate)--如果数据库中有cat就会删掉,不成功会报错local res, err, errcode, sqlstate = db:query("drop table if exists cats")--这里不能打印res[ngx.say(res)]否则也会报错,可能是res数据类型不能直接被打印的原因,使用cjson转换成json再打印此时可以,我在机器上测试过local cjson = require "cjson"ngx.say("result: ", cjson.encode(res))if not res thenngx.say("bad result: ", err, ": ", errcode, ": ", sqlstate, ".")returnend--创建表cat,两个字段,一个key一个nameres, err, errcode, sqlstate =db:query("create table cats ".. "(id serial primary key, ".. "name varchar(5))")if not res thenngx.say("bad result: ", err, ": ", errcode, ": ", sqlstate, ".")returnendngx.say("table cats created.")--这个数据库是老师提前建好并插入了数据,我不知道数据,这里执行直接就报错找不到表t_emp然后结束执行了res, err, errcode, sqlstate =db:query("select * from t_emp")if not res thenngx.say("bad result: ", err, ": ", errcode, ": ", sqlstate, ".")returnendlocal cjson = require "cjson"--res查询结果需要使用cjson.encode(res)被转换成json才能被输出到浏览器,即使没查到内容也需要使用cjson先转换才能输出,直接输出会报错,且cjson必须使用cjson.lua进行引入ngx.say("result: ", cjson.encode(res))--这是连接池,复用连接local ok, err = db:set_keepalive(10000, 100)if not ok thenngx.say("failed to set keepalive: ", err)returnend主配置文件
nginx.confxxxxxxxxxxworker_processes 1;events {worker_connections 1024;}http {include mime.types;default_type application/octet-stream;lua_shared_dict shared_data 1m;lua_code_cache off;sendfile on;keepalive_timeout 65;server {listen 888;server_name localhost;location /lua {default_type text/html;#手动设置响应内容的字符编码格式供浏览器参考,响应内容出现中文浏览器不会乱码charset utf-8;#执行连接操作redis的脚本文件content_by_lua_file lua/mysql.lua;}location / {root html;index index.html index.htm;}error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}}响应效果
🔎:没有t_emp数据,这里直接报错该表不存在结束脚本执行了
课堂实例
模板引擎
模板引擎加数据源加业务逻辑就可以做成类似SpringMVC的应用,就可以在OpenResty中开发出自己想要的应用;OpenResty的模板引擎
lua-resty-template是OpenResty提供的第三方插件,Git和官方文档:https://github.com/bungle/lua-resty-template🔎:这套模板引擎比较复杂,且实现的功能比较全面,已经和jsp、thymeleaf这种模板引擎很类似了
使用模板引擎对标签进行渲染
🔎:模版引擎还有很多其他的配置,能够让页面变得更加复杂,这里只是简单介绍
在OpenResty的根目录下创建模板目录
tpl,在模板目录下创建模板文件view.html🔎:模板由html和标签【标签用两个大括号括起来】组成
xxxxxxxxxx<html><body><h1>{{message}}</h1></body></html>在主配置文件中配置模板文件存放位置
🔎:在location下进行模板文件根目录配置
set $template_root /usr/local/openresty/tpl;,引入Lua脚本文件content_by_lua_file lua/tpl.lua;,表示在文件tpl中渲染模板
xxxxxxxxxxworker_processes 1;events {worker_connections 1024;}http {include mime.types;default_type application/octet-stream;lua_shared_dict shared_data 1m;lua_code_cache off;sendfile on;keepalive_timeout 65;server {listen 888;server_name localhost;location /lua {default_type text/html;#OpenResty会读取该变量$template_root把对应目录设置为模板的根目录set $template_root /usr/local/openresty/tpl;charset utf-8;#使用lua脚本tpl.luacontent_by_lua_file lua/tpl.lua;}location / {root html;index index.html index.htm;}error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}}安装
lua-resty-template模块默认OpenResty下没有该模块,下载2.0版本
lua-resty-template-2.0.tar.gz;将文件上传到lualib目录下并解压缩
【解压目录结构】
xxxxxxxxxx[root@nginx1 lua-resty-template-2.0]# ll总用量 80-rw-rw-r--. 1 root root 3074 2月 24 2020 Changes.md-rw-rw-r--. 1 root root 210 2月 24 2020 dist.inidrwxrwxr-x. 3 root root 19 2月 24 2020 lib-rw-rw-r--. 1 root root 1498 2月 24 2020 LICENSE-rw-rw-r--. 1 root root 848 2月 24 2020 lua-resty-template-dev-1.rockspec-rw-rw-r--. 1 root root 40 2月 24 2020 Makefile-rw-rw-r--. 1 root root 57916 2月 24 2020 README.md将
lua-resty-template-2.0/lib/resty/目录下的所有文件挪到lualib/resty目录下🔎:将这两个文件挪动到
/usr/local/openresty/lualib/resty目录下,挪动后剩下文件lua-resty-template-2.0可以直接删掉
xxxxxxxxxx[root@nginx1 resty]# ll总用量 24drwxrwxr-x. 2 root root 64 2月 24 2020 template-rw-rw-r--. 1 root root 23230 2月 24 2020 template.lua
在
/usr/local/openresty/lua/目录下创建lua脚本tpl.luaxxxxxxxxxx-- Using template.new--引入模板引擎的lib包/lualib/resty/templatelocal template = require "resty.template"--通过模板文件创建view对象local view = template.new "view.html"--设置模板文件中的变量值view.message = "Hello, World!"--使用上面的参数值去渲染模板文件页面数据view:render()-- Using template.render-- template.render("view.html", { message = "Hel11lo, Worl1d!" })访问效果
模版引擎的基本用法
🔎:讲的很粗糙,细节看官方文档学习,弹幕说这个语法和django很像
模板文件
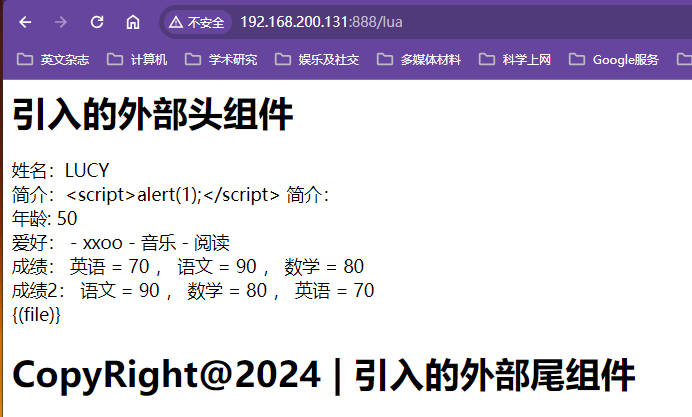
/tpl/view.htmlxxxxxxxxxx<!--{(header.html)}表示引入另外一个模板文件,因为没有找到目标原始文件,显示效果中直接把文件名输出了,可以做不常改变文件的头和尾-->{(header.html)}<body>{# 这个是注释标签 #}<!--将参数值name变成大写,{* string.upper(name) *}能将英文字母大写-->{# 不转义变量输出 #}姓名:{* string.upper(name) *}<br/>{# 转义变量输出 #}{# {{description}}直接将内容作为字符串响应,即便是一段html标签也会原样输出,简单的说就是将特殊符号转义成字符串 #}简介:{{description}}{# {* description *}是不转义特殊字符,直接原样输出字符串,这个字符串如果是html标签或者js代码会在浏览器进行渲染 #}简介:{* description *}<br/>{# {* age + 10 *}也可以在其中引入变量和运算符做一些运算 #}年龄: {* age + 10 *}<br/>{# {% for i, v in ipairs(hobby) do %}对hobby数组进行循环遍历输出,ipairs是lua语言中的for循环写法,这就很像lua的写法,怀疑这个模版最后会转成lua语言执行,和jsp很像,且在循环体中也可以输出原生html的内容,比如- xxoo #}爱好:{% for i, v in ipairs(hobby) do %}{% if v == '电影' then %} - xxoo{%else%} - {* v *}{% end %}{% end %}<br/>成绩:{% local i = 1; %}{# 这是对键值对数据Map进行遍历,应该在lua中称为table #}{% for k, v in pairs(score) do %}{# i的初始值为1,当i大于1的时候输出逗号,即每个键值对用逗号隔开 #}{% if i > 1 then %},{% end %}{* k *} = {* v *}{% i = i + 1 %}{% end %}<br/>成绩2:{{# score2是数组,数组的每个元素是table,这是对数组中的table进行遍历,数组通过下标拿数据 #}}{% for i = 1, #score2 do local t = score2[i] %}{% if i > 1 then %},{% end %}{* t.name *} = {* t.score *}{% end %}<br/>{# {-raw-}中间的内容不解析,即便是标签也不解析,直接原样输出{(file)} #}{-raw-}{(file)}{-raw-}{(footer.html)}nginx/lua/tpl.luaxxxxxxxxxxlocal template = require("resty.template")--这个是模板引擎缓存,调试的时候可以将模板引擎缓存关掉,上线以后再打开,缓存打开以后更改模板可能不会发生变化template.caching(false)local context = {title = "测试",name = "lucy",description = "<script>alert(1);</script>",age = 40,hobby = {"电影", "音乐", "阅读"},score = {语文 = 90, 数学 = 80, 英语 = 70},score2 = {{name = "语文", score = 90},{name = "数学", score = 80},{name = "英语", score = 70},}}template.render("view.html", context)主配置文件
nginx/conf/nginx.confxxxxxxxxxxworker_processes 1;events {worker_connections 1024;}http {include mime.types;default_type application/octet-stream;lua_shared_dict shared_data 1m;lua_code_cache off;sendfile on;keepalive_timeout 65;server {listen 888;server_name localhost;location /lua {default_type text/html;#OpenResty会读取该变量$template_root把对应目录设置为模板的根目录set $template_root /usr/local/openresty/tpl;charset utf-8;#使用lua脚本tpl.luacontent_by_lua_file lua/tpl.lua;}location / {root html;index index.html index.htm;}error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}}测试效果
🔎:因为这里没有
header.html和footer.html,这两文件一般放不咋变化的头和尾,因为找不到对应的文件,所以直接把文件名打印出来了🔎:
header.html和footer.html都是模板文件,根目录都是和主模板文件view.html在同一个模板根目录tpl下

tpl/header.htmlxxxxxxxxxx<h1>引入的外部头组件</h1>tpl/footer.htmlxxxxxxxxxx<h1>CopyRight@2024 | 引入的外部尾组件</h1>头尾拼接效果
OpenResty应用示例
Redis缓存+mysql+模板输出构建的小应用,以一个sql作为key缓存到redis中,如果通过sql从redis中获取不到对应的结果就去mysql中查询,如果没有结果就去连接mysql去数据库查,然后将查询结果扔到redis中,如果下次还有相同的sql查询,直接去redis中去获取;获取到数据以后直接渲染到模板文件上响应给客户端;这是很简陋的版本,千万不要到线上直接使用
不建议使用这种方式去做比较复杂的业务,因为业务一复杂,lua脚本就要分文件,调试的时候非常难搞,一旦出错,就要看
error.log,从源码上一条一条去排查错误,而且异常信息不好捕捉和展示,甚至可能出现语法错误导致项目无法运行
搭建流程
tpl.lua
🔎:这里需要创建表
t_temp,还要插入数据,换个谷粒学院的edu_chapter表来进行实现🔎:这个sql是针对请求写死在脚本中的,用户只知道点了按钮,不知道sql
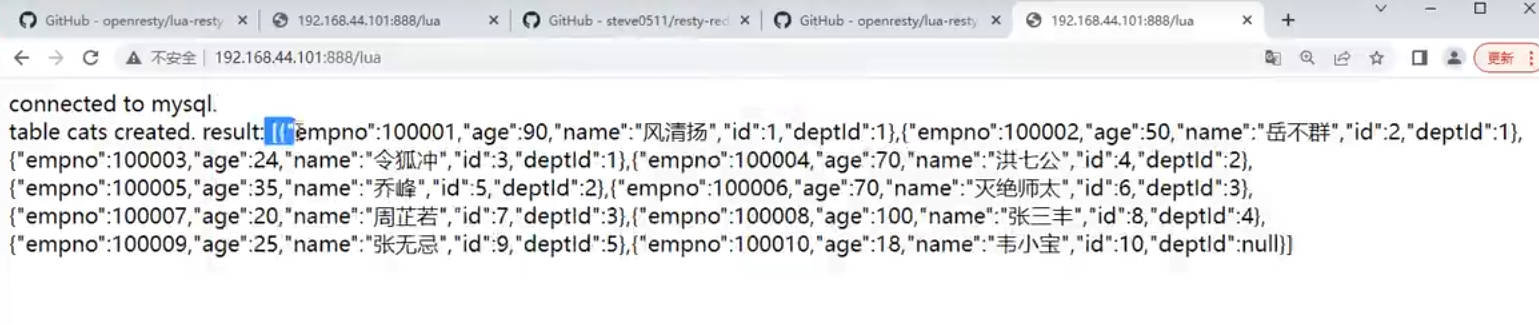
xxxxxxxxxx--引入cjson工具cjson = require "cjson"--定义key即sql语句sql="select * from edu_chapter"--引入连接redis的工具local redis = require "resty.redis"local red = redis:new()red:set_timeouts(1000, 1000, 1000) -- 1 seclocal ok, err = red:connect("127.0.0.1", 6379)if not ok thenngx.say("failed to connect: ", err)returnendlocal res, err = red:get(sql)if not res thenngx.say("failed to get sql: ", err)returnendif res == ngx.null thenngx.say("sql"..sql.." not found.")--引入连接mysql的工具local mysql = require "resty.mysql"local db, err = mysql:new()if not db thenngx.say("failed to instantiate mysql: ", err)returnenddb:set_timeout(1000) -- 1 seclocal ok, err, errcode, sqlstate = db:connect{host = "192.168.200.131",port = 3306,database = "zhangmen",user = "root",password = "Haworthia0715",charset = "utf8",max_packet_size = 1024 * 1024,}ngx.say("connected to mysql.<br>")--这里从mysql查询的数据应该会自动被转换成table类型的数据res, err, errcode, sqlstate = db:query(sql)if not res thenngx.say("bad result: ", err, ": ", errcode, ": ", sqlstate, ".")returnend--ngx.say("result: ", cjson.encode(res))--把table类型数据转成json字符串,带转义符号,这个格式的json不能因为有转义符号在在线json格式化时会报错,直接以res作为value存入redis会存入res的内存地址ok, err = red:set(sql, cjson.encode(res))if not ok thenngx.say("failed to set sql: ", err)returnendngx.say("set result: ", ok)--第一次请求去mysql中拉数据并不会渲染,这里直接把数据存入redis后直接打印set result:ok就直接结束了returnendlocal template = require("resty.template")template.caching(false)local context = {title = "测试",name = "lucy",description = "<script>alert(1);</script>",age = 40,hobby = {"电影", "音乐", "阅读"},score = {语文 = 90, 数学 = 80, 英语 = 70},score2 = {{name = "语文", score = 90},{name = "数学", score = 80},{name = "英语", score = 70},},--要把json字符串转换成table对象才能在模版文件中进行渲染zhangmen=cjson.decode(res)}template.render("view.html", context)view.html
xxxxxxxxxx{(header.html)}<body>{# 不转义变量输出 #}姓名:{* string.upper(name) *}<br/>{# 转义变量输出 #}年龄: {* age + 10 *}<br/>{# 循环输出 #}爱好:{% for i, v in ipairs(hobby) do %}{% if v == '电影' then %} - xxoo{%else%} - {* v *}{% end %}{% end %}<br/>成绩:{% local i = 1; %}{% for k, v in pairs(score) do %}{% if i > 1 then %},{% end %}{* k *} = {* v *}{% i = i + 1 %}{% end %}<br/>成绩2:{% for i = 1, #score2 do local t = score2[i] %}{% if i > 1 then %},{% end %}{* t.name *} = {* t.score *}{% end %}<br/>{# 中间内容不解析 #}{-raw-}{(file)}{-raw-}掌门:{# 下一行会直接显示table的内存地址,注意注释里面不能嵌套标签,否则会报错 #}{* zhangmen *}<br>{% for i = 1, #zhangmen do local z = zhangmen[i] %}{{# 且标签外不能添加大括号 #}{* z.gmt_create *},{* z.course_id *},{* z.id *},{* z.gmt_modified *},{* z.sort *},{* z.title *}}<br>{% end %}<br/>{(footer.html)}测试效果
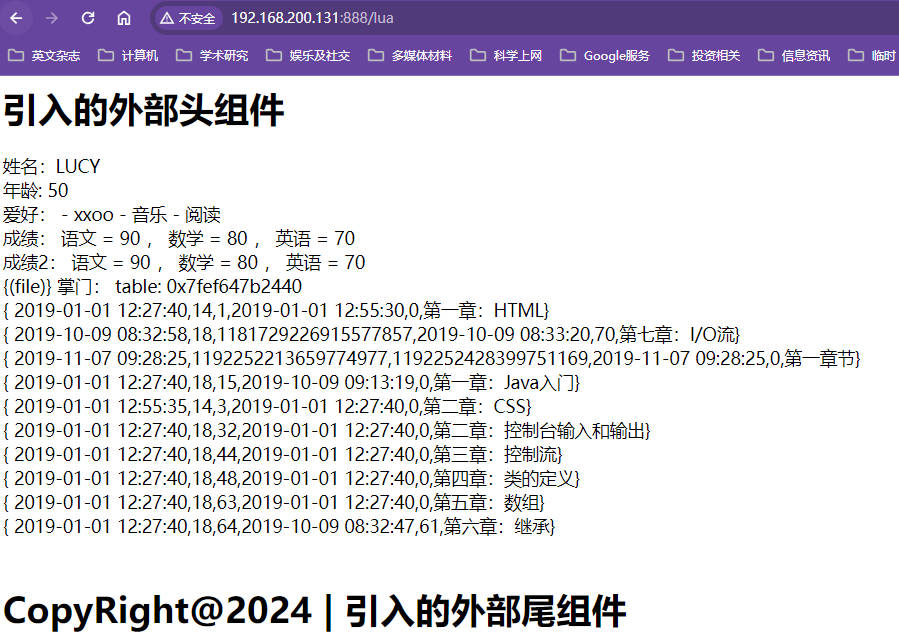
使用的sql
xCREATE TABLE `edu_chapter` (`id` char(19) NOT NULL COMMENT '章节ID',`course_id` char(19) NOT NULL COMMENT '课程ID',`title` varchar(50) NOT NULL COMMENT '章节名称',`sort` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '显示排序',`gmt_create` datetime NOT NULL COMMENT '创建时间',`gmt_modified` datetime NOT NULL COMMENT '更新时间',PRIMARY KEY (`id`),KEY `idx_course_id` (`course_id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 ROW_FORMAT=COMPACT COMMENT='课程';## Data for table "edu_chapter"#INSERTINTO `edu_chapter`VALUES('1','14','第一章:HTML',0,'2019-01-01 12:27:40','2019-01-01 12:55:30'),('1181729226915577857','18','第七章:I/O流',70,'2019-10-09 08:32:58','2019-10-09 08:33:20'),('1192252428399751169','1192252213659774977','第一章节',0,'2019-11-07 09:28:25','2019-11-07 09:28:25'),('15','18','第一章:Java入门',0,'2019-01-01 12:27:40','2019-10-09 09:13:19'),('3','14','第二章:CSS',0,'2019-01-01 12:55:35','2019-01-01 12:27:40'),('32','18','第二章:控制台输入和输出',0,'2019-01-01 12:27:40','2019-01-01 12:27:40'),('44','18','第三章:控制流',0,'2019-01-01 12:27:40','2019-01-01 12:27:40'),('48','18','第四章:类的定义',0,'2019-01-01 12:27:40','2019-01-01 12:27:40'),('63','18','第五章:数组',0,'2019-01-01 12:27:40','2019-01-01 12:27:40'),('64','18','第六章:继承',61,'2019-01-01 12:27:40','2019-10-09 08:32:47');